
Intro
If a disaster occurs, every business needs a set of recovery strategies and solutions prepared in advance to protect and restore business-critical applications. According to Business Impact Analysis (BIA), RPO, RTO, and MTD are defined.
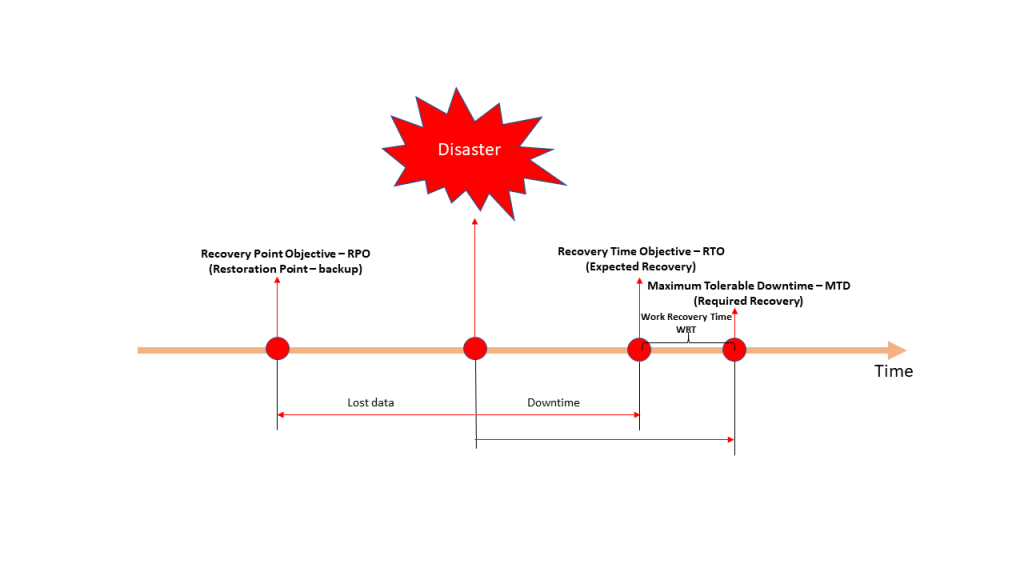
RPO value is how much data is allowed to lose but measured in time. RPO is defined based on the amount of data that can be lost within a period of time before significant harm to the business occurs. RPO is used to determine the frequency of backups.
RTO values represent how long it takes to achieve restoration goals before reaching maximum tolerable downtime (MTD).
MTD value is how long it takes to restore from the disaster to a fully operational state. MTD is defined based on the quantity of time applications, and business processes can be down without causing damage to a business. Often MTD is overlooked, from an IT perspective, because the WRT (Work Recovery Time) procedure takes time to check that all systems are synchronized, and data needs to be checked and tested to be sure that they are in the proper sequence.
Disaster Recovery
The concept of disaster recovery presents strategies and solutions, which have traditionally been the way to respond to all sorts of outages (natural, hardware & software failures and human-made mistakes). It presents a set of procedures for returning access and functionality of IT infrastructure to a fully operational state after a catastrophic interruption. So, disaster recovery is a manual task for recovering workloads at a recovery site from replicated data. Tools like VMware Site Recovery Manager (SRM) can be used for recovery automation.
Disaster Avoidance
The question is, can disaster be avoided? Is there a way to be proactive and keep data safe even if a disaster happens? The answer is yes! Instead of recovering data, disaster avoidance forecast and prepare for a disaster before it happens. Disaster avoidance enables the highest level of resiliency for business-critical applications and virtual machines hosting them, which ensures application availability in case of disaster.
Over the years, we have had solutions with synchronous replication functionality, but these solutions were complex to implement and very expensive. Usually, deployment of those solutions required Professional Services engagement, and maintenance was spread to multiple vendors.
This blog will present three solutions based on VMware Metro Storage Cluster (vMSC), which are simple to deploy and maintain and come with a price worth thinking about. These solutions will provide better IT infrastructure resilience than traditional disaster recovery solutions. But, to achieve multi-level protection, you should have a third site that will act as a traditional DR site. Also, in case of VM guest OS failures or ransomware attacks, a backup solution is needed to provide you with the ability to restore VMs and guest OS files from multiple restore points. For backup, we recommend a solution that leverages vSphere APIs for I/O Filtering (VAIO) like Cohesity, which delivers near-zero RPOs and rapid RTOs.
vMSC – vSphere Metro Storage Cluster
vMSC is a storage configuration that combines replication with array-based clustering. In this design, the datastore, which spans both sites, must be accessible from both sites. These configurations are usually implemented in environments where disaster and downtime avoidance is a crucial requirement. Every disk writes synchronously at both sites. It ensures data consistency regardless of the location. So, this architecture requires significant bandwidth between two sites, and very low latency (up to 10ms RTT).
With traditional synchronous replication, the primary-secondary relationship between active (primary) LUN and mirror (secondary) LUN exists. The replication needs to be stopped to access secondary LUN, and secondary LUN is presented to hosts with different LUN ID.
With vMSC, storage subsystems must be able to read and write to both locations, and disk writes are committed synchronously at both locations to ensure that data is always consistent.
Based on how hosts access storage, we have two types of vMSC configurations:
- Uniform host access configuration: hosts from both sites are connected to all storage nodes on both sites.
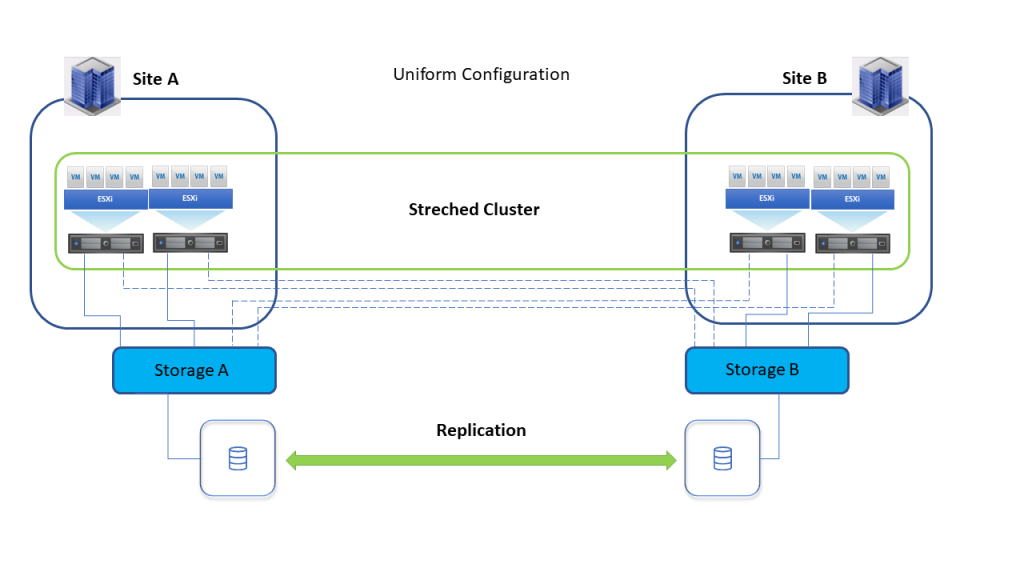
With uniform host access configuration, in the event of storage outage on site A, hosts from site A will access identical LUN through Storage B.
- Non-uniform host access configuration: hosts from each site are connected only to the storage nodes within the same site.
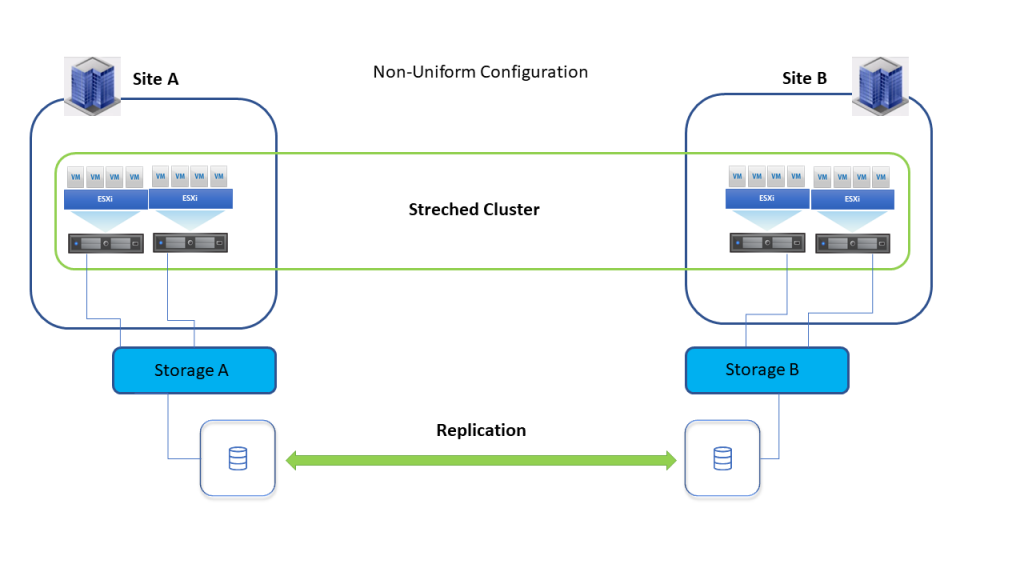
With non-uniform host access configuration, in the event of storage outage on site A, VMs from site A will be restarted on site B by vSphere HA.
As of the licensing, from the VMware side, there is no minimum license requirement. You can create stretched cluster with any edition. If automated workload balancing is required, the vSphere Enterprise Plus license requirement is from either a CPU or storage perspective.
Pure Storage Active Cluster
Pure Storage® Purity ActiveCluster is a fully symmetric active/active bidirectional replication solution that provides synchronous replication for zero RPO and automatic transparent failover for zero RTO. ActiveCluster feature offers active/active storage clustering within and across multiple physical locations. These physical locations can be a different rack in a single data center or utterly different data centers with up to 11ms of round-trip network latency.
No additional hardware or licenses are required. Synchronous replication implies synchronized writes between arrays protected in NVRAM on both arrays before being acknowledged to the host. Transparent failover ensures non-disruptive failover between synchronously replicating arrays with automatic resynchronization and recovery.
Purity ActiveCluster comprises three core components: The Pure1 Mediator, active/active clustered array pairs (Purity version 5.0.0 or higher), and stretched storage containers.
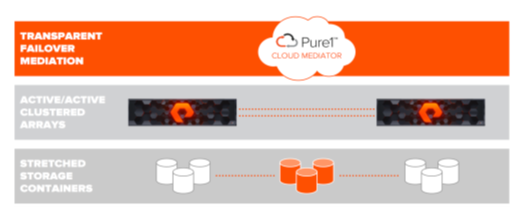
- Pure1 Mediator is a required component that is used to determine which array will continue to serve data services if an outage occurs in the environment. Mediator must be located in a 3rd site that is in a separate failure domain from either site where arrays are located. Each array must have independent network connectivity to the Mediator such that a single network outage does not prevent both arrays from accessing the Mediator. If a failover is required, the connection to the Mediator occurs from the controller management ports. The preferred option is to use a cloud mediator, provided by Pure, but if arrays do not have internet access, an on-prem Mediator (OVA image) is available for deployment.
- ActiveCluster storage (volumes) can be accessed by hosts using either a uniform or non-uniform SAN topology. Advantage of using Pure Storage Purity ActiveCluster:
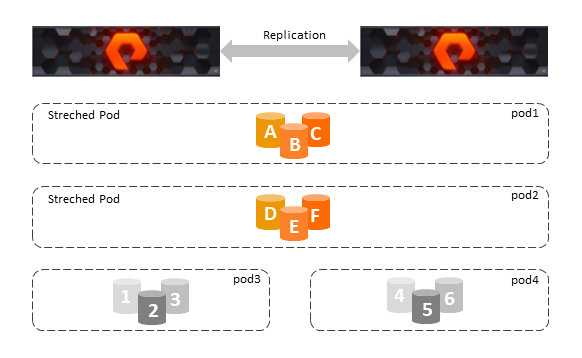
- In ActiveCluster, volumes in stretched pods are read/write on both arrays
- The optimized path is defined on a per host-to-volume connection basis using a predefined-array option.
- A Pod is a stretched storage container that defines a set of objects that are synchronously replicated together. The array can support multiple Pods. A pod can exist on just one or two arrays simultaneously with synchronous replication.
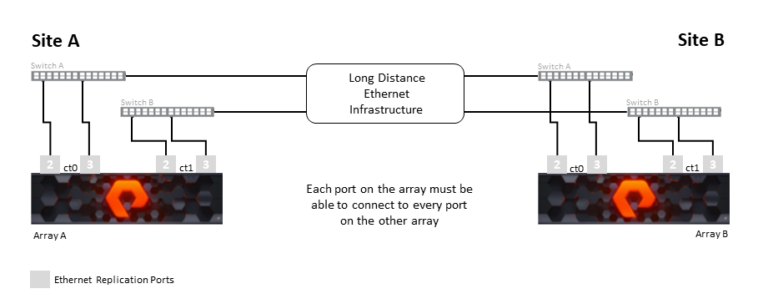
The replication network supports connecting arrays with up to 11ms of round-trip time (RTT) latency between the arrays. Two ethernet ports per controller, connected via a switched infrastructure, are required for replication connectivity. For redundant configurations using dual switches, each controller must connect to each local switch, and switching infrastructure must allow all replication ports to connect to each other.
ActiveCluster is designed to be genuinely active/active, where either array can maintain I/O services to synchronously replicated volumes. Uniform storage access configuration has failover-less maintenance. In the event of an array failure, or replication link failure causing one array to stop I/O services, the hosts experience only the loss of some storage paths and continue to use other paths to the available array. In a non-uniform storage access configuration, VMs running on hosts that have lost access to the array will be restarted on the hosts connected to the other storage array.
ActiveCluster includes an automatic way for applications to transparently failover without user intervention, using Pure1 Cloud Mediator to provide a quorum mechanism. Transparent failover between arrays in ActiveCluster is automatic.
In the event of replication network failure, split-brain scenario, both arrays will pause I/O within standard host I/O timeout and reach out to the Mediator to determine which array can continue to serve I/O for each replicated pod. When the ActiveCluster mediator race begins, the result can be unpredictable. That means, in the case of non-uniform host configuration, lack of mediator race predictability can lead to disruptive restart for the application running on stretched pod volume. ActiveCluster provides a failover preference feature that enables the storage administrator to influence the outcome of the resulting race. The preference feature gives the preferred array, for each pod, additional 6 seconds in its race to the Mediator.
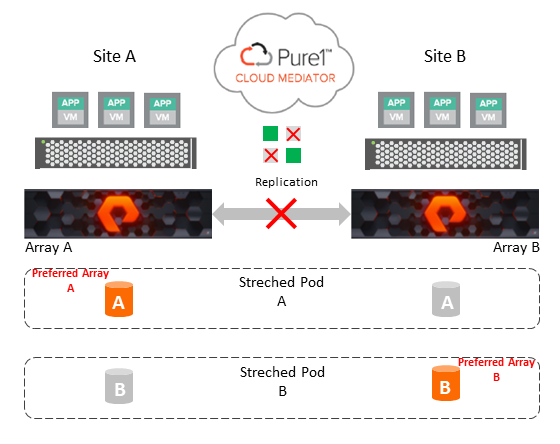
In non-uniform host connectivity setting failover, preference is recommended best practice. Disruptive restarts will occur only in cases when one FlashArray is offline or the entire site is lost.
Purity 5.3 introduced ActiveCluster built-in Mediator pulling. This feature allows both arrays to agree a mediator race winner for each stretched pod if both arrays cannot reach the Mediator. Pod failover preference is used to determine the winner (if set). If no pod failover preference were set, the winner would be selected automatically. In the following table availability of stretched pod volumes is given based on different solution components failure.
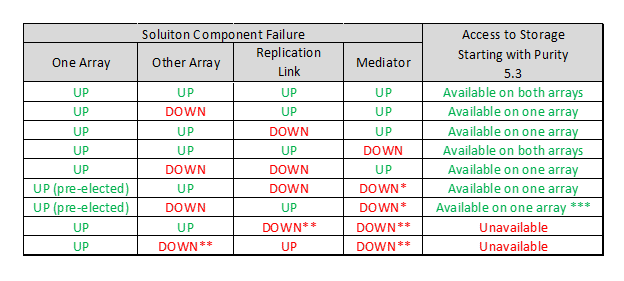
* Pre-Election completes before second component failure.
** Simultaneous failures of components.
*** Assumes the “Other Array” was not Pre-Elected. If the Pre-Elected array fails, stretched
pod volumes are unavailable.
Resynchronization and recovery are automatic. The storage administrator intervention is no longer needed to recover and resynchronize ActiveCluster replication.
NetApp SnapMirror business continuity (SM-BC)
ONTAP 9.8 introduces SnapMirror Business Continuity (SM-BC), enabling workloads to be served simultaneously on both clusters. SM-BC is a continuously available storage solution, available for NetApp ONTAP® running on NetApp AFF or NetApp All SAN Array (ASA) storage systems. SM-BC supports only two-node HA clusters (either AFF or ASA); no additional hardware is required.
Compared to SnapMirror Synchronuos (SM-S), which require manual failover or to use DR management solution for failover, SM-BC enables automated failover without any manual intervention. SM-BC maintains the LUN identity between the two copies, so applications see them as a shared LUN. Application granularity is enabled using a consistency group, with automatic transparent failover to the secondary copy with no data loss. Besides business continuity with granular application management, SM-BC enables additional use cases like leveraging 2nd copy for test and dev. An ONTAP mediator is required on the 3rd site to monitor two ONTAP clusters and orchestrate automated failover if the primary storage system is offline. SM-BC does not require extra licensing as long as your cluster has Data Protection or Premium Bundle.
SM-BC provides the following benefits:
- Application granularity for business continuity
- Automated failover with the ability to test failover for each application.
- LUN identity remains the same, so the application sees them as a shared virtual device.
- Ability to reuse secondary with the flexibility to create instantaneous clones for application usage for dev-test, UAT, or reporting purposes, without impacting application performance or availability.
- Simplified application management using consistency groups to maintain dependent write-order consistency.
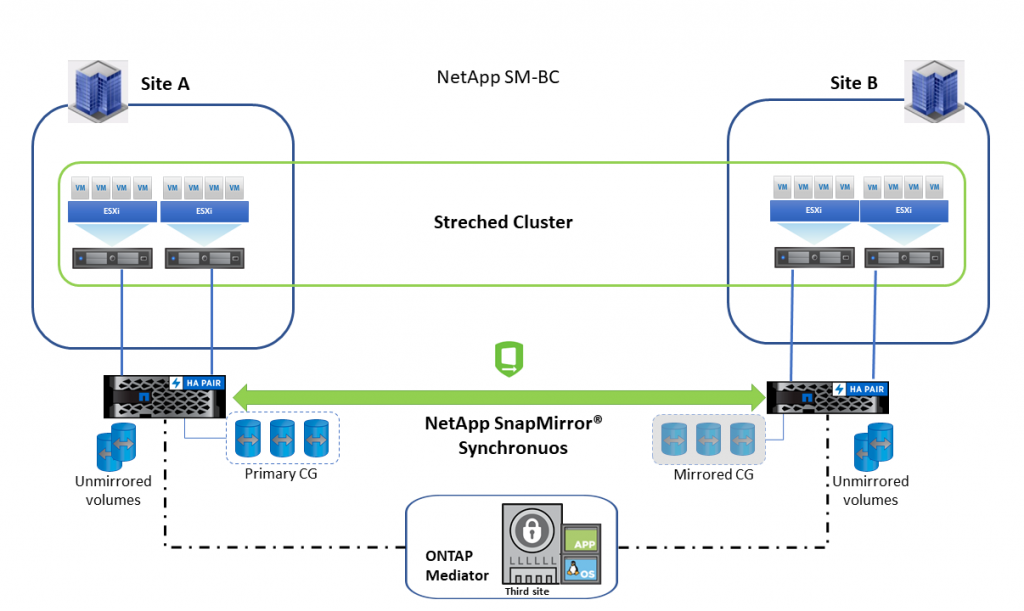
SM-BC architecture provides active workloads on both clusters, where primary workloads can be served simultaneously from both clusters. The data protection relationship is created between the source storage system and destination storage system by adding the application-specific LUNs from different volumes within a storage virtual machine (SVM) to the consistency group. The purpose of a CG is to take simultaneous snapshot images of multiple volumes, thus ensuring crash-consistent copies of a collection of volumes at a point-in-time (PiT). Under normal operations, the enterprise application writes to the primary consistency group, synchronously replicating this I/O to the mirror consistency group. Even though two separate copies exist in the data protection relationship, because SM-BC maintains the same LUN identity, the application host sees this as a shared virtual device with multiple paths while only one LUN copy is being written to at a time. When a failure occurs and the primary storage system goes offline, the ONTAP Mediator detects this failure and enables seamless application failover to the mirror consistency group. This process fails over only a specific application without the need for the manual intervention or scripting previously required for failover.
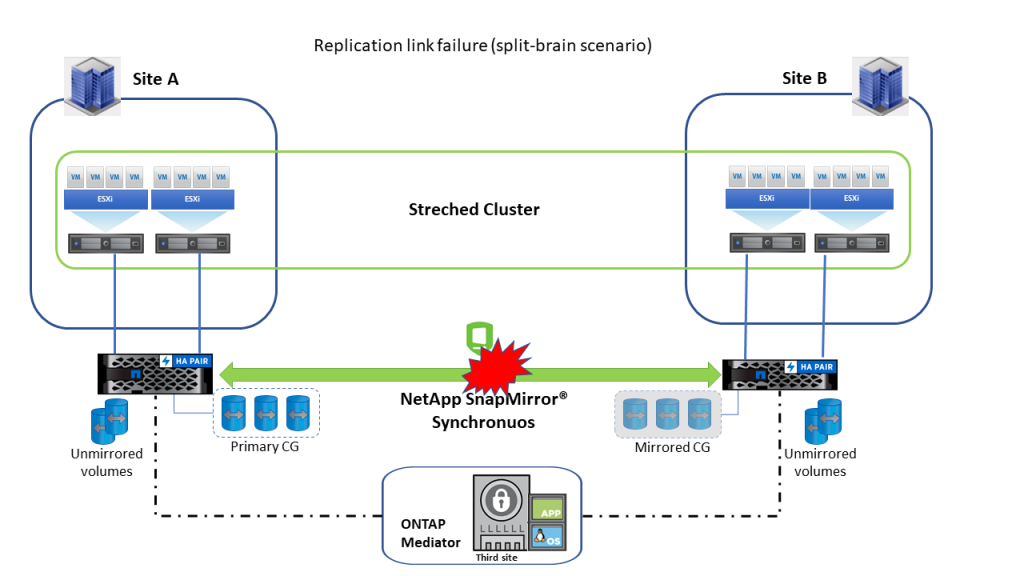
In case of replication link failure, NetApp® ONTAP® Mediator detects link failure. Primary LUN continues to serve I/O, to the hosts, and all paths from the secondary cluster report illegal request/LU not found.
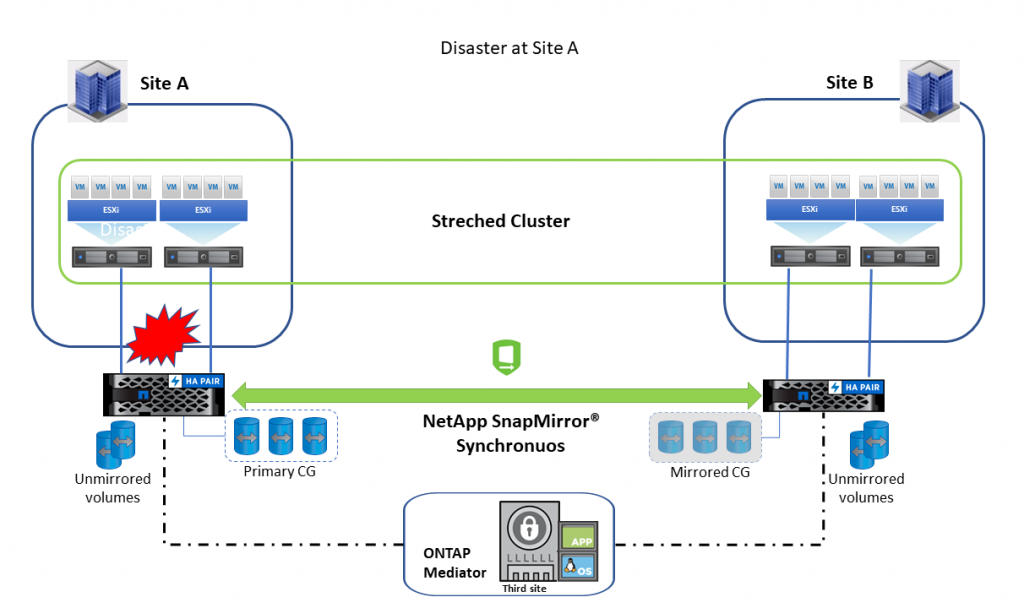
If a disaster occurs in Site A, Mediator detects it and informs the Secondary site, and the Secondary LUN continues to serve I/O to the hosts. When Site A comes back online, Mediator will establish a relationship in the reverse direction and assign Secondary to Site A volumes. After the relationship reaches a sync state, planned failover can be performed to restore normal operations.
In case of disaster at Site B, primary LUN continues to server I/O to the hosts.
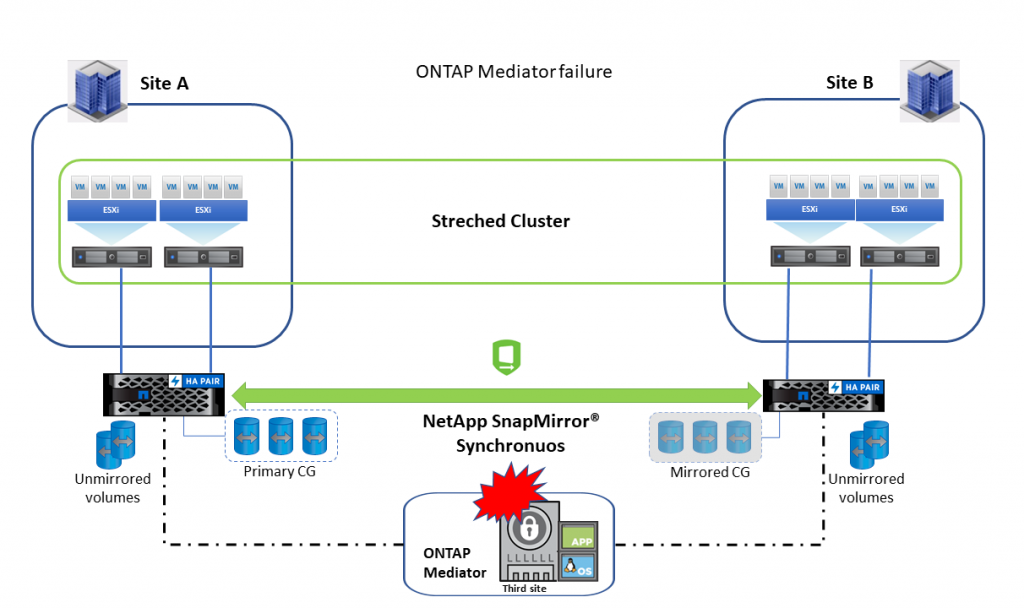
In the case of NetApp® ONTAP® Mediator failure (virtual machine), primary LUN continues to server I/O to the hosts, and the relationship is in sync. Because ONTAP Mediator is not available, AUFO (automatic unplanned) or PFO (planned) failover is impossible.
vSAN Streched Cluster
Compared with previous solutions based on physical Storage Arrays, vSAN Stretched Cluster is based on VMware vSAN software-defined storage architecture. vSAN is a storage solution that runs on standard x86 hardware. It is integrated into vSphere kernel and fully integrated with other vSphere functionalities such as HA, DRS, vMotion. vSAN Datastore consists of all local disks aggregated into a single datastore shared by all hosts in the cluster.
Initial setup and maintenance are much more manageable than previous solutions, as the configuration is carried out from the vSphere client. Due to the way that vSAN works, there is no need for configuring storage replication. The deployment of vSAN Stretched Cluster is wholly done from vSphere wizard. The minimum for deployment is 2+1 witnesses and a maximum of 40 ESXi hosts +1 witnesses (vSAN 7 U2). On the 3rd site witness (physical or virtual) is deployed.
Benefits of the vSAN Stretched Cluster configuration are:
- Disaster avoidance and planned failover (maintenance)
- Active-Active Datacenter
- Easy to manage with a single vSphere vCenter
- Site-level high availability to maintain business continuity
- Automatic recovery in case one of the sites is unavailable
- Simple and faster implementation, compared to the Stretched cluster using traditional storage systems
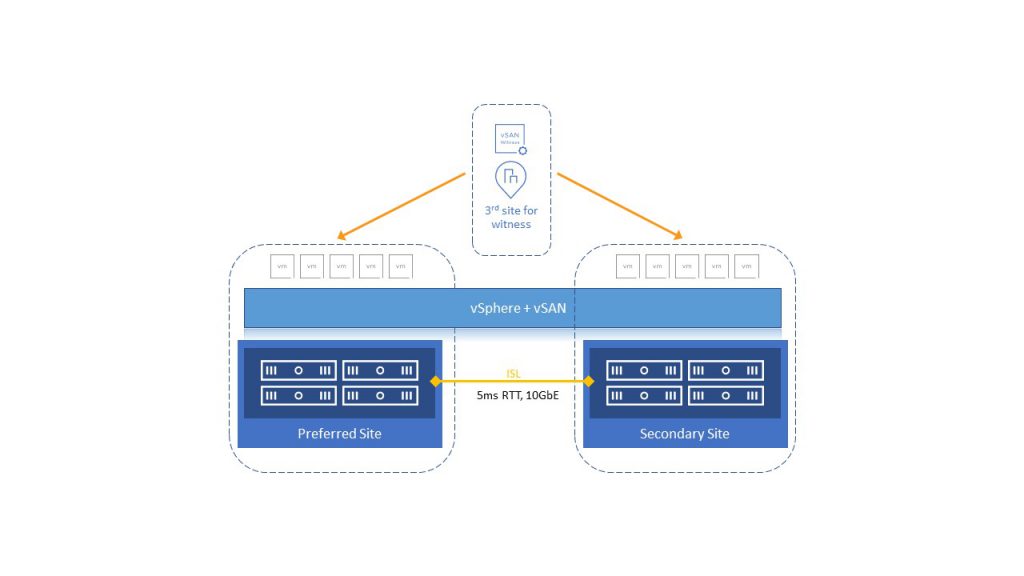
vSAN stretched cluster is an HCI solution that extends between three distant locations or Fault Domains (FD); these include preferred, secondary, and witness. During initial configuration, it is needed to decide which site will be preferred, and this is important if we have a split-brain (ISL failure) scenario. In this scenario, even if the Secondary Site is healthy, vSphere HA will restart VMs from the Secondary Site to Preferred Site.
In vSAN, we use Storage policies to define virtual machine storage requirements for performance and availability. Besides the default storage policy between active sites (Raid1), with vSAN 6.6, we have an additional option for Local Protection and Site Affinity. On the site, local protection, or FTT, refers to the number of failures (0 to 3), and it can be raid1 or raid5/6. With the Site Affinity Policy, we can define for which objects protection across sites is not desired.
Like in previous solutions, we have different scenarios if some of the essential components fail
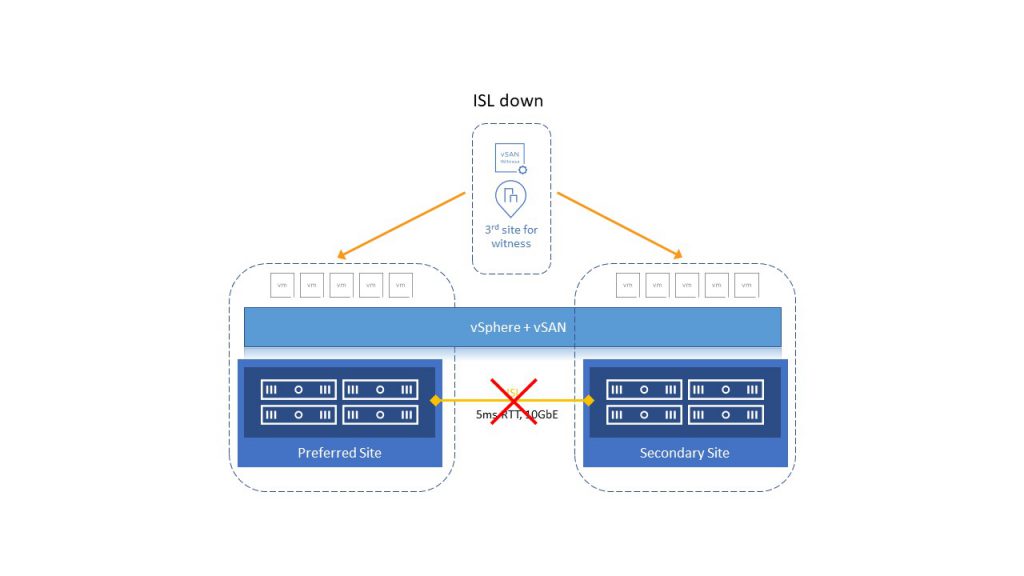
If the cluster loses communication between sites (ISL down), a quorum will be established between the Preferred site and Witness. The vSphere HA will restart VMs from the Secondary site to the Preferred site. That is why it is essential to determine, in the initial deployment, which of the two sites will be preferred.
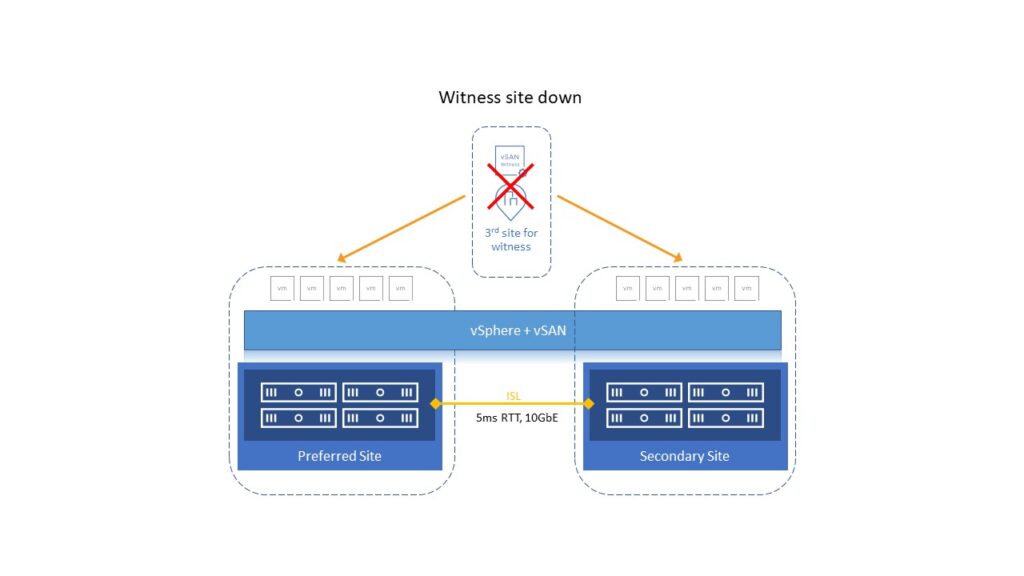
If the Witness site is down (becomes inaccessible or network isolated), all VMs continues to run on their sites.
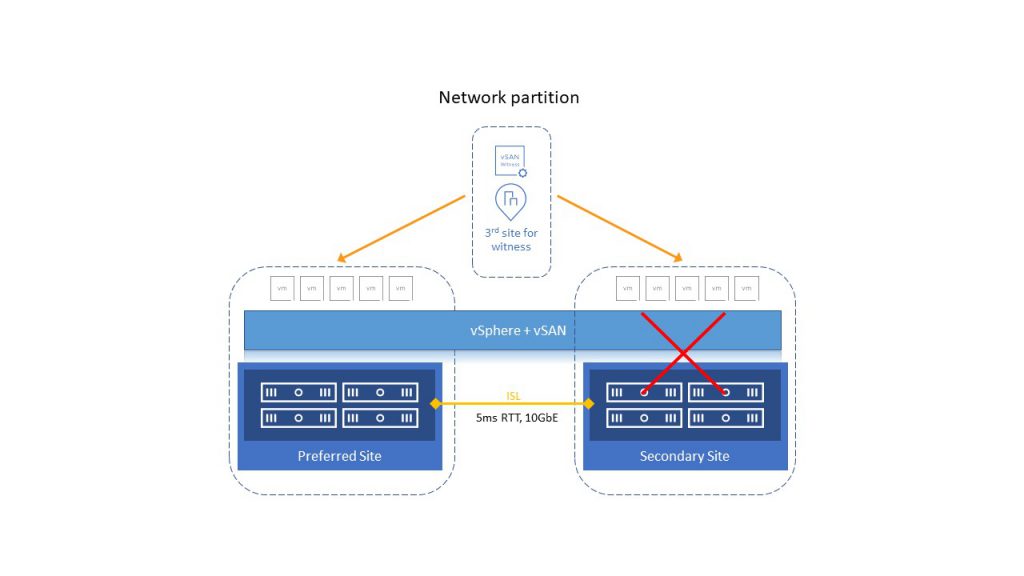
If one of the sites is down or becomes network-isolated, the quorum will be established between surviving site and the Witness site. The HA on the other site will restart all VMs from the lost or isolated site.
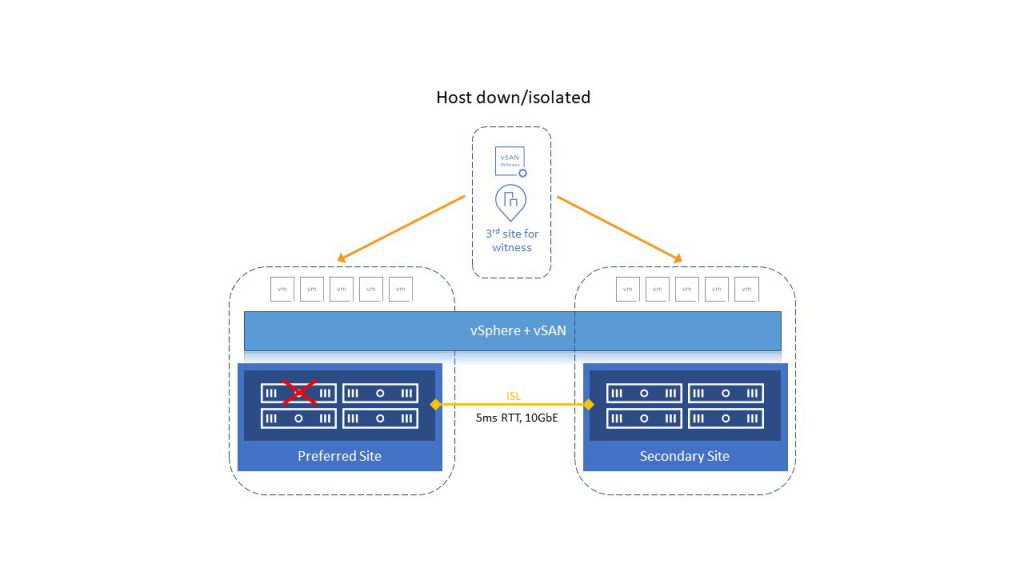
If the cluster loses one of the hosts, HA will restart those VMs on the other host. If the host does not recover in 60 minutes, all components on that host will be automatically recreated on one of the remaining hosts.
Conclusion
With vMSC implementation, same benefits that high-availability cluster provide to a local site are available within two data centers which are geographically dispersed. Cluster is spread over two locations and managed by a single vCenter. VMs in vMSC can be migrated between sites with vSphere vMotion and vSphere Storage vMotion. Distance between data centers is limited, often within the metropolitan area (RTT requirement).
Disaster avoidance significantly reduces the probability that a disaster will occur and provides better resilience than traditional disaster recovery. But to achieve multi-level protection third site is needed to act as a traditional DR.