
In my first blog post, the topic I write about, Software Defined Disaster Avoidance – The Proper Way, is a story that we at Braineering have successfully turned into reality twice so far. The two stories have different participants (clients), but they both face the same fundamental challenges. The stories occur in two distinct periods, the first in 2019 and the second one in 2020.
Introduction
Both clients are from Novi Sad and belong to the public sector. Both provide IT products to many public services, administrations, and bodies without which life in Novi Sad would not run smoothly. Over 3000+ users use IT products and services hosted in their Datacenters daily. Business applications such as Microsoft Exchange, SharePoint, Lync, MS SQL, and Oracle are just some of the 400+ virtual servers that their IT staff takes care of, maintains, or develops daily.
Key Challenges
At the time, both users’ IT infrastructure was more or less the standard IT infrastructure we see in most clients. It consists of a primary Datacenter and a Disaster Recovery Datacenter located at another physically remote location.
The primary and DR site is characterized by traditional 3-Tier architecture (compute, storage, and network) Figure 1.
The hardware located on the DR site usually operates using more modest resources and older generation equipment than the primary site. It is replicated to a smaller number of the most critical virtual servers. Both clients had storage base replication between Datacenters, and VMware SRM was used to solve automatic recovery.
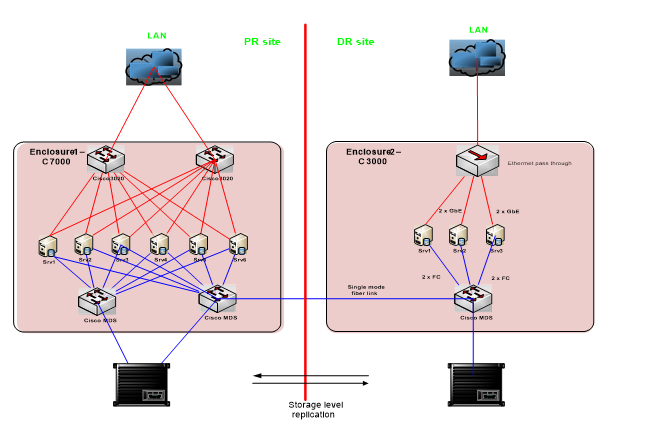
Even though the clients are different, they had common vital challenges:
- Legacy hardware
- different server generations: G7, G8, G9
- storage systems End of service life.
- Inability to keep up with the latest versions because of legacy hardware.
- vSphere
- VMware SRM
- Storage OS or microcode
- Weak and, for today’s standards, modest performance
- 8 Gb SAN, 1Gb LAN
- Slow storage system disks (SATA and SAS)
- Storage system fragmentation
- vCPU: pCPU ratio
- Expensive maintenance – again due to legacy hardware
- Refurbished disks
- EOSL (End of service life), EOGS (End of general support)
- Limited scalability, the expansion of CPU, memory, or storage resources
When new projects and daily dynamic user requests to upgrade existing applications are also considered, both clients were aware that something urgent needed to be done about this issue.
Requirements for the Future Solution
The future solution was required to be performant, with low latency and easy scaling with high availability. The goal is to reduce any unavailability to a minimum with low RTO and RPO. The future solution must also be simple to maintain, and migration, i.e., switching to it, should be as painless as possible. If possible, remove/reduce overprovisioning and long-term planning and doubts when the need for expansion (by adding new resources) arises.
And, of course, the future solution must support all those business and in-house applications hosted on the previous IT infrastructure.
The Chosen Solution
After considering different options and solutions, both users eventually opted for VMware vSAN. As the user opted for vSAN as their future solution in both cases, we at Braineering IT Solutions suggested vSAN in the Stretched Cluster configuration to maximize all the potential and benefits that such a configuration brings. To our delight, both users accepted our proposal.
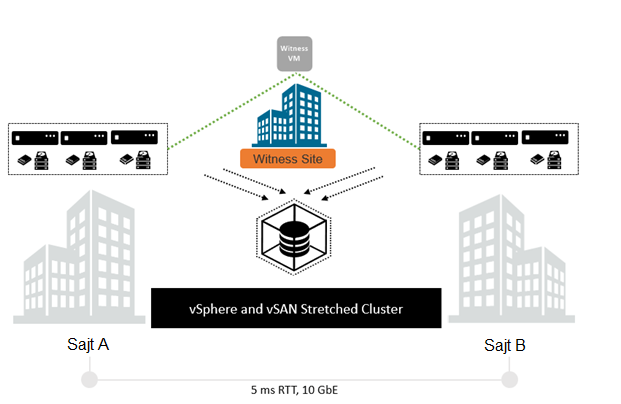
Stretched Cluster
What is the vSAN Stretched Cluster? It is an HCI cluster that stretches between two distant locations. (Figure 2)
The chosen future solution fully meets all the requirements mentioned above: it supports all clients’ business and in-house applications. In the All-Flash vSAN configuration, they can deliver a vast number of low-latency IOPS. The Scale-Up and Scale-Out architecture allow you to quickly expand resources by adding additional resources to existing nodes (Scale-Up) or adding new nodes to the cluster (Scale-Out).
It is easy to manage; everything is operated from a single vCenter. Existing backup and DR software solutions are supported and work seamlessly. And finally, as the most significant benefit of vSAN in the Stretched Cluster configuration, we have disaster avoidance and planned maintenance.
The benefits of the vSAN Stretched Cluster configuration are:
- Site-level high availability to maintain business continuity.
- Disaster avoidance and planned maintenance
- Virtual server mobility and load-balancing between sites
- Active-Active Datacenter
- Easy to manage – a single vSphere vCenter.
- Automatic recovery in the case of one of the sites’ unavailability
- Simple and faster implementation compared to the Stretched cluster of traditional storage systems.
The Advantages of the Implemented Solution
The most important advantages:
New servers: The possibility of tracking new versions of VMware platform solutions. A better degree of consolidation and faster execution of virtual machines
Network 10Gbps: 10Gbps datacenter network infrastructure raises network communications to a higher level and degree of speed.
HCI: Scale-out platform, infrastructure growth by adding nodes. Compute, network, and storage resources are converted into building blocks. Replacement of existing storage systems with the vSAN platform in All-flash configuration.
SDDC: A platform that introduces new solutions such as network virtualization, automation systems, day-two operations …
DR site: New DR site dislocated to a third remote location. It is retaining existing VMware SRM and vSphere Replication technology.
Saving: Consolidation of all VMware licenses, consolidation of hardware maintenance of new equipment. Savings have been achieved in the maintenance of old HW systems.
Stretched cluster: Disaster-avoidance system that protects services and data, and recovers with automated procedures, even in a complete site failure scenario
The End Solution
Today’s IT infrastructure for both clients is shown in Figure 3.
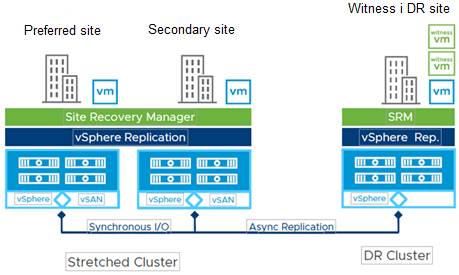
The preferred site and Secondary site, the Active-Active cluster, use one common stretched vSAN datastore. All I/O operations on this stretched datastore are synchronized. VMware Replication replicates the 25 most critical virtual servers on the DR site, and that replication is asynchronous. For automated and orchestrated recovery on the DR site in the event of a disaster on a stretched cluster, both users retained the solutions they had previously implemented, VMware SRM.
Thanks for this detail solution presentation for a real case scenario.
An insightful article that highlights the significance of software-defined disaster avoidance for businesses to ensure continuous operations and mitigate potential risks.